La suite de cette fiche guide est en : Un peu de patience !!!
V.1.5 - Dernière mise à jour : 28/03/2025
L'objectif est de :
- Réaliser des traitements automatisés ou semi-automatisés
pour extraire l'information recherchée
- Contrôler la pertinence :
- des classifications ;
- des typologies.
par des matrices d'erreurs.
Pour classer les pixels par groupes homogènes =>
- utilisation de l'information spectrale contenue dans un ou plusieurs canaux satellitaux
On effectue des regroupements spectraux :
- manuels
ou
- automatiques
Objectif :
assigner un thème (eau, forêt, urbain dense...) à chaque pixel de l'image.
Résultat :
une mosaïque de pixels qui appartiennent à des thèmes différents plus ou moins jointifs
=> représentation thématique
Deux classes sont à distinguer :
classes d'information : les catégories que l'on veut identifier ;
classes spectrales : groupes de pixels ayant les mêmes caractéristiques dans les différentes bandes spectrales.
Il faut les faire correspondre !
Une classe d'information très large comme la forêt (Code CORINE 31) peut être subdivisée en sous-classes :
- feuillus (Code CORINE 311)
- conifères (Code CORINE 312)
- mais pas mélangées (Code CORINE 313)
- Pourquoi ?
L'analyste doit déterminer leur intérêt pour les conserver ou non !
Il existe deux grandes catégories de classification, les méthodes de classification dites :
- supervisées
- non supervisées.
Ces méthodes ne prennent pas en compte le voisinage spatial des pixels. Pour cela il faut recourir aux techniques de segmentation.
Pour les classifications supervisées :
on va demander au logiciel de rechercher dans l'image les pixels les plus proches d'une signature type.
Pour les classifications non-supervisées,
le logiciel regroupe les pixels dont les caractéristiques spectrales sont :
- les plus proches ;
- parfois majoritaires
puis l'utilisateur recherche ce que les catégories représentent.
La suite de cette fiche guide est en : Un peu de patience !!!
Synonyme : matrices de confusion*
Pour des données qualitatives
Permet d'évaluer l'intensité de la liaison entre des données de référence et le résultat d'une classification.
- Pour réaliser cette évaluation, c'est la fonction ERRMAT qui est proposée dans TerrSet.
ERRMAT utilise deux fichiers images qui contiennent :
- Les données de référence issues d'un échantillonnage de terrain
- la majorité des pixels est à zéro ;
- quelques pixels contiennent les valeurs enquêtées
- Le résultat de la classification
- peut être complet ou incomplet :
- tout pixel n'est pas obligé d'être affecté à une catégorie ;
- toutes les catégories ne sont pas forcément présentes ;
- mais contient les catégories dans le même ordre que l'image de référence.
- À l'aide de ces deux images, ERRMAT génère une matrice d'erreur (cf. tableau 1) et un résumé statistique.
tab. 1 - Matrice d'erreurs ou de confusion
Vraies catégories (image de référence) Catégories produites (classification)
1 2 3 4 5 Total Erreurs de commission 1 513 0 23 0 0 536 0,0429 2 0 2928 2 1 293 3224 0,0918 3 58 320 565 0 188 1131 0,5004 4 0 22 0 143 226 391 0,6343 5 1 53 14 4 838 910 0,0791 Total 572 3323 604 148 1545 6192
Erreurs d'omission 0,1031 0,1189 0,0646 0,0338 0,4576
0,1946
- La lecture en est la suivante :
- Les pixels sur la diagonale sont bien classés.
Il y a concordance entre les "vérités terrain*" et la cartographie
- Hors de la diagonale, ce sont les erreurs de classification.
- Les erreurs de classifications sont totalisées et divisées par le total marginal. On les répartie en :
- Erreurs d'omission dans le cas où des points de référence d'une catégorie sont attribués à une autre catégorie ;
- Erreurs de commission dans le cas contraire où les points d'une catégorie lui sont attribués par erreur.
- En général, on considère :
- les Erreurs d'omission comme un moyen de juger l'assignation (classification) ;
- les Erreurs de commission comme un moyen d'améliorer cette assignation.
- En complément, ERRMAT fournit les valeurs de l'indice KIA (Kappa Index of Agreement) :
- totales ;
- par catégories.
C'est un indice de précision relative.
- Quand le :
KIA = -1 => la concordance est nulle
KIA ± 0 => la concordance est peu significative
KIA = +1 => la concordance est très forte
- Voir le module CROSSTAB et ses notes pour le détail des calculs de l'indice KIA (Kappa Index of Agreement) :
- Quelle est la quantité de cellules identiques dans chaque catégorie ?
- Ces cellules identiques sont-elles aux mêmes endroits ?
Proche de ERRMAT, cette méthode mesure l'accord entre deux images catégorielles (entiers ou octets).
L'une est l'image de référence, l'autre celle à tester.
Procède par le calcul de plusieurs KIA (Kappa Indices of Agreement) basés sur :- accord dû au hasard ;
- accord à l'emplacement...
Ce module permet de tester la validité des classifications :
- par strates ;
- en faisant varier la
résolution ;
Le module ROC (Relative Operating Characteristic) est destiné à l'évaluation de la prédiction d'un modèle.
Pour répondre à la question :Le fichier en sortie du ROC est un fichier texte qui informe de l'AUC (Area Under the Curve)
Si l'AUC est égale à :
1 => l'adéquation spatiale
est parfaite entre la classe témoin et celle de la carte réalisée ;
0.5 => c'est le compromis trouvé si la distribution est due au hasard !
fig. 1 - Exemple d'AUC pour le module ROC (ROC = 59.9%)
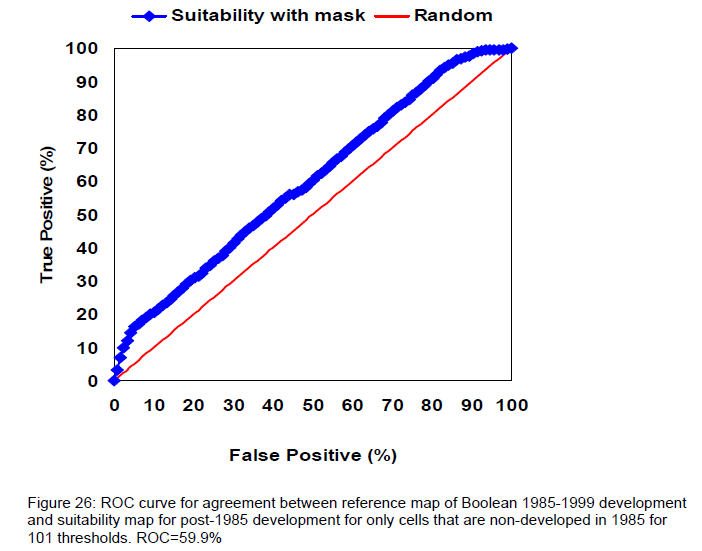
Source : PONTIUS
2006 p.42
fig. 2 - Autre exemple d'AUC pour le module ROC (ROC pour différents
seuils)
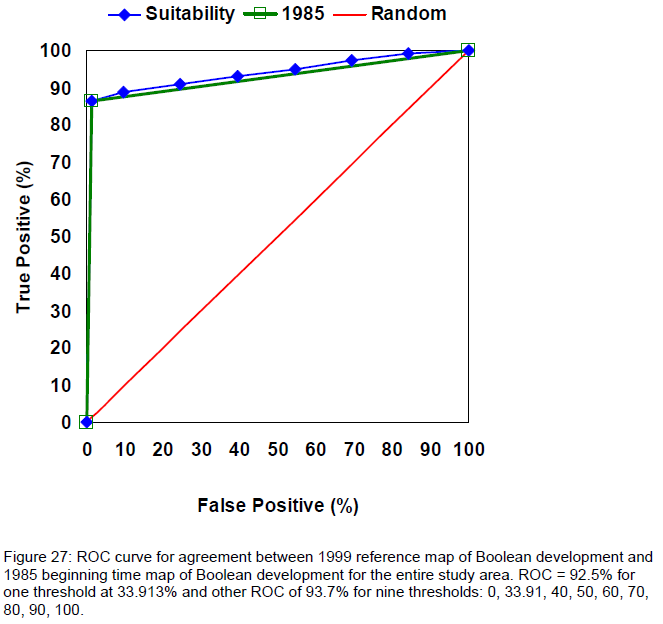
Source : PONTIUS
2006 p.42
Il existe bien d'autres types de classification :
Classifications par segmentation
Classifications texturales
Communiquez-moi sur la plateforme Moodle, à la rubrique "Questions de cours", les réponses aux questions suivantes :
Question n°4.4.1.
a)
b)
c)
Question n°4.4.2.
a)
b)
NB : les mots suivis de "*" font partie du vocabulaire géographique, donc leur définition doit être connue. Faites-vous un glossaire.
