Cette reconnaissance relève normalement d'un plan d'échantillonnage.
fig. 1 - Parcelles d'entraînement pour la classification supervisée (fichier H87TM4)
Source : EASTMAN 1997 p.94
(avec l'autorisation du Clark Labs - exercice librement inspiré du didacticiel d'Idrisi32 par Michelle GIBOIRE - adaptation Vincent GODARD)
Objectifs : classer l'ensemble des pixels d'une image à partir d'un échantillon de zones d'entraînement
Fonctions décrites dans ce TD : Digitize, Delete feature, MAKESIG, SIGCOMP, SCATTER, MINDIST, MAXLIKE, PIPED, FISHER, WINDOW, RECLASS, Symbol Workshop, ERRMAT
Chaque catégorie d'occupation du sol a une signature spectrale qui lui est propre.
Il y a deux méthodes de classification des données télédétectées :
- les classifications supervisées ;
- les classifications non-supervisées.
Pour les classifications supervisées :
on va demander au logiciel de rechercher dans l'image les pixels les plus proches d'une signature type.
Pour les classifications non-supervisées :
le logiciel regroupe les pixels dont la signature est la plus proche, puis l'utilisateur recherche ce que les catégories représentent.
- Les étapes d'une classification supervisée sont les suivantes :
-Certaines classifications sont dites :
"dures" => affectation du pixel à un groupe unique ;
"douces" => évaluation du degré d'appartenance du pixel à tous les groupes.
Ce sont les classifications "dures" qui sont étudiées ici. Les développements théoriques concernant ces méthodes de classifications sont consultables dans la chapitre Classification of Remotely Sensed Imagery dans le IDRISI Guide to GIS and Image Processing Volume 2.
La figure n°1 montre la localisation des différentes catégories d'occupation du sol.
Cette reconnaissance relève normalement d'un plan d'échantillonnage.
fig. 1 - Parcelles d'entraînement pour la classification supervisée (fichier H87TM4)
Source : EASTMAN 1997 p.94
a) A chaque type de couvert d'occupation du sol sera assigné un identifiant entier unique.
A chaque type peut correspondre une ou plusieurs parcelles d'entraînement.
- Pour utiliser ensuite la palette qualitative par défaut d'IDRISI, respecter les numéros suivants:
- Shallow water (eaux peu profondes)
- Deep water (eaux profondes)
- Agriculture
- Urban (zones urbanisées)
- Deciduous (feuillus)
- Coniferous (résineux)
- Pour vectoriser les parcelles d'entraînement, il faut :
b) Afficher le fichier H87TM4 avec la palette Grey 256
- Pour vectoriser la 1ère parcelle d'entraînement :
- Sélectionner l'outil de vectorisation à l'écran à l'aide de l'icône suivante :
- Créer un fichier vecteur appelé TRSITES
- en mode Polygon ;
- fichier symboles => Qual256
- entrer le numéro de l'identifiant (le 2 de l'eau profonde pour commencer, par exemple)
- valider
- Commencer la vectorisation avec le bouton de gauche
- Terminer avec celui de droite
- Choisir des pixels homogènes (ne pas mélanger l'eau et la berge ...)
- Pour annuler un polygone (terminez-le, le cas échéant), utiliser l'icône suivante :
- Pour vectoriser la 2e parcelle d'entraînement :
- Re-sélectionner l'outil de vectorisation à l'écran
- Garder le même identifiant si c'est un autre polygone du même thème
- Sinon changez-le !
- Combien doit-il y avoir de pixels d'entraînement par thème ?
En règle générale, il faut pour chaque thème :
10 fois le nombre de bandes d'enregistrement du capteur
- Pour SPOT 4 => 10 * 4 pixels, soit 40 pixels par thème
- Pour TM => 10 * 7 pixels, soit 70 pixels par thème, etc.
c) Une fois tous les polygones de chaque thème vectorisés, il faut sauver le fichier à l'aide de l'icône suivante :
- Afficher TRSITES sur H87TM4
Il faut maintenant créer les informations statistiques concernant les réflectances spectrales de chaque parcelle d'entraînement.
d) Lancer MAKESIG depuis le menu Image Processing/Signature Development
- Choisir :
- comme type de fichier d'entraînement => Vector
- son nom => TRSITES
- entrer le nom des catégories d'occupation du sol (Enter signature file name)
- E_peu_pr
- Eau_prof
- Agricult
- Zon_urba
- Feuillus
- Resineux
- laisser cocher => Create Signature Group file
Il doit s'appeler TRSITES
Ce fichier de signatures groupées facilite l'utilisation de plusieurs modules.
Pour en savoir plus sur les fichier de signatures groupées cliquez ici ...
Valider par OK
- le nombre de bandes => 7
- le nom des bandes à traiter :
- Band1 => H87TM1
- Band2 => H87TM2
- Band3 => H87TM3
- Band4 => H87TM4
- Band5 => H87TM5
- Band6 => H87TM6
- Band7 => H87TM7
Pour en savoir plus sur le capteur TM de Landsat ...
Là aussi, un fichier de signatures groupées facilite l'utilisation de plusieurs modules. On peut le créer avant de la sélectionner par Insert Layer Group.
Valider par OK
f) Vérifier l'existence du fichier des signatures par IDRISI File Explorer du menu File.
g) Lancer SIGCOMP depuis le menu Image Processing/Signature Development
- Sélectionner le fichier des signatures groupées
Insert ... => TRSITES
- choisir de comparer leur moyenne
1) Quel est le canal qui permet le mieux de différencier les "végétations" ?
h) Lancer à nouveau SIGCOMP
- choisir cette fois-ci de ne comparer que :
- les zones urbanisées (4)
- les conifères (6)
- entrer leur nom
- choisir de comparer leur moyenne plus le minimum et le maximum
Il y a chevauchement pour certaines bandes
=> signe de confusion radiométrique dans les parcelles tests
2) Dans quelle signature relève-t-on la plus forte variabilité (dispersion des signatures) ? Pourquoi ?
Chaque pixel de l'image a une valeur dans chacune des bandes enregistrées, c'est sa signature.
Elle va être comparée au fichier des parcelles d'entraînement à l'aide de différents algorithmes de classification*.
- Procédure :
- à l'aide des parcelles d'entraînement, l'algorithme de classification :
- calcule
- la moyenne des valeurs spectrales :
- de chaque catégorie d'occupation du sol ;
- dans chaque bande du capteur.
- la distance de chacun des pixels de l'image à chaque moyenne
- affecte chaque pixel au groupe dont la moyenne lui est la plus proche.
La distance utilisée est la distance euclidienne.
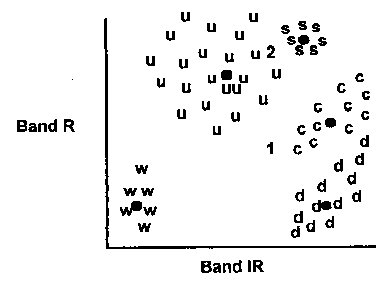
- La figure 2 illustre ce concept :
fig. 2 - Histogramme bidimensionnel représentant la moyenne de chaque catégorie
Source : LILLESAND et KIEFFER - 1979 - Remote Sensing and Image Interpretation. New York, John Wiley & Sons in EASTMAN 1997 p.90- les lettres minuscules représentent les signatures spectrales* suivantes ;
u => urban
c=> corn (maïs)
s => sand (sable)
w => water
d => deciduous (feuillus)
- les points noirs sont les moyennes de chaque catégorie d'occupation du sol ;
- les chiffres 1 et 2 représentent 2 pixels à comparer.
- le pixel 1 est du maïs (c pour corn) ;
- le pixel 2 est de l'urbain (u pour urban).
j) Utiliser la fonction SCATTER depuis le menu Image Processing/Signature Development.
- Choisir :
- File 1 (Y-axis) : H87TM3 (canal du rouge)
- File 2 (X-axis) : H87TM4 (canal du PIR)
- Laisser cocher par défaut : Natural log (ln) of pixels counts
- Sélectionner le nom du Signature group file : TRSITES
- Donner un nom au fichier résultat : SCATTER
- Créer un Signature Plot File => TRSITES
Valider par OK
j) Acceptez le fichier vecteur créé par SCATTER.
- Ajouter (Add layer) ce fichier vecteur SCATTER
- Palette Qual256
- Promenez votre curseur sur le scattegramme (ou histogramme bidimensionnel).
- A quoi correspondent :
- les coordonnées X et Y ?
Les niveaux de réflectance entre 0 et 255.
- Zoomer sur la partie basse gauche de l'histogramme bidimensionnel*
- les couleurs sur le scattegramme ?
La palette des couleurs vues sur l'histogramme bidimensionnel représente la densité (le logarithme de la fréquence)
- les couleurs brillantes => les fortes concentrations des pixels ;
- les couleurs sombres => les faibles concentrations des pixels
- et les boîtes en couleurs ?
Les boîtes représentent le bon ou mauvais recouvrement des signatures (deux écarts-types de part et d'autre de la moyenne) des parcelles d'entraînement et la totalité du spectre réfléchi pour ces deux bandes.
- des trous => des signatures spectrales* vous échappent ;
- des chevauchements => des thèmes appartiennent à plusieurs signatures.
Ne pas hésiter à reprendre certaines signatures en re-saisissant des parcelles tests.
k) Vérifier que l'affichage automatique de la légende est coché dans le menu File/User Preferences
l) Lancer MINDIST depuis le menu Image Processing/Hard Classifiers.
- Sélectionner :
- le type de distance => Raw (sans standardisation par la moyenne et l'écart-type)
- la distance maximum de "collecte"=> Infinite
- Sélectionner le bouton Insert signature group file et choisir => TRSITES
- Nommer l'image de sortie => MINDISTRAW
Valider avec Next =>
- Conserver tous les canaux d'enregistrement
Valider par OK
- Changer la Palette en Qual256 si nécessaire
- Quel est le thème dominant ?
- Il peut être intéressant de tenir compte de la dispersion des réflectances autour de la moyenne
On utilise alors la standardisation* (centrage par la moyenne, réduction par l'écart-type).
Un pixel est rattaché à une catégorie en fonction de sa valeur en nombre d'écart-type.
Si la distribution des pixels d'entraînement d'un thème donné est proche d'une distribution en cloche (C.f. figure 3), alors n'importe quel pixel de ce thème a :
- 67 p. 100 de chances d'appartenir à l'intervalle
moyenne des réflectances du groupe ± 1 écart-types
- 95 p. 100 de chances d'appartenir à l'intervalle
moyenne des réflectances du groupe ± 2 écart-types
- etc.
Pour en savoir plus sur les conditions d'application : c.f. la fiche mémo mem31enq.htm du cours d'enquête.
fig. 3 - Concentration des individus dans une distribution en cloche (normale)
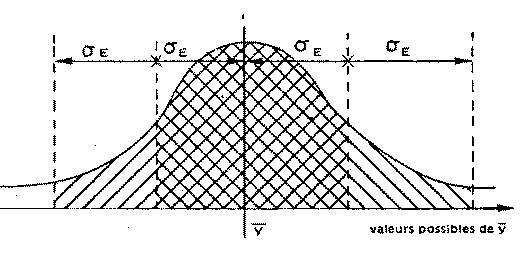
Source BRION 1982, p.11
La répartition des individus est connue de part et d'autre de la moyenne*
quelque soit la valeur de l'écart-type*
.
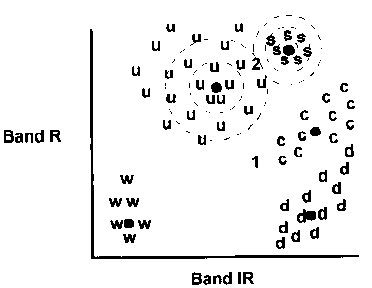
Sur la figure 4, le pixel 2 n'est plus rattaché aux sables (sand) comme sur la figure 2 mais à l'urbain
Il est à :
- deux écarts-types de l'urbain
- trois écarts-types des sables
fig. 4 - Histogramme bidimensionnel et classification par la distance minimum standardisé
Source : LILLESAND et KIEFFER - 1979 - Remote Sensing and Image Interpretation. New York, John Wiley & Sons in EASTMAN 1997 p.91
m) Relancer MINDIST
- Modifier
- le type de distance => Normalized standard deviation (standardisation)
- Nommer l'image de sortie => MINDISTNORMAL
3) Comment décrire les effets de la distance standardisée (quels sont les thèmes qui progressent ?) ?
Cette méthode s'appuie sur une fonction de répartition probabiliste des réflectances dans les sites d'entraînement, répartition basée sur la statistique bayesienne. Le programme évalue la probabilité qu'un pixel appartienne à chacune des classes et l'affecte là où la probabilité est la plus forte.
fig. 5 - Histogramme bidimensionnel et classification par le maximum de vraisemblance
Source : LILLESAND et KIEFFER - 1979 - Remote Sensing and Image Interpretation. New York, John Wiley & Sons in EASTMAN 1997 p.92
- Donner le même poids à chaque classe
Cocher Use equal prior probabilities for each signature => probabilité égale pour chaque classe
- Sélectionner l'insertion d'un Signature group file : TRSITES
- Choisir de classer tous les pixels
Cocher Proportion to exclude => 0% (classify all pixels)
- Vérifiez le nombre de signatures dans la fenêtre de saisie
- Nommer l'image de sortie => MAXLIKE
- Inscire un titre descriptif
Valider avec Next =>
- Conserver tous les canaux d'enregistrement
Valider par OK
- Quelle est la probabilité associée à chaque signature ?
Le maximum de vraisemblance est la méthode :
- la plus lente,
mais si les sites d'entraînement sont bons
- c'est la plus précise
Cette avant dernière méthode crée des "boîtes" utilisant :
- des unités d'écart-type (Z-score)
ou
- le minimum et le maximum
des valeurs de réflectances calculées sur les sites d'entraînement.
Si un pixel tombe dans les limites de la "boîte de signatures",
alors il est assigné à cette catégorie.
- C'était la méthode la plus rapide quand les procésseurs étaient peu rapides :
- l'option avec Min. et Max. permettait un coup d'oeil global ;
- mais souvent la classification résultante était peu fiable.
C'est due à la corrélation* de l'information dans les bandes spectrales, qui donne des formes de cigares aux nuages de points (cf. fig. 5).
Comme on le voit sur la figure 6, les boîtes prennent mal en compte ces allongements et de plus se chevauchent.
fig. 6 - Histogramme bidimensionnel et classification hypercubique
Source : LILLESAND et KIEFFER - 1979 - Remote Sensing and Image Interpretation. New York, John Wiley & Sons in EASTMAN 1997 p.93
o) Lancer PIPED
- Choisir l'option Min/Max
- Sélectionner l'insertion d'un Signature group file : TRSITES
- Nommer l'image de sortie => PIPEDMINMAX
- Inscire un titre descriptif
Valider avec Next =>
- Conserver tous les canaux d'enregistrement
Valider par OK
- À quoi correspondent les pixels en noir ?
Ce sont les pixels hors des "boîtes de signature"
La classification par hypercubes est extrèmement sensible aux valeurs extrêmes, surtout avec l'option Min/max.
L'option par défaut de PIPED utilise l'écart-type à la place du Min/Max pour atténuer l'effet des valeurs extrêmes.
p) Relancer PIPED comme précédemment mais :
- Choisir l'option Z-score
- À quoi correspondent la valeur 1,96 dans la fenêtre de saisie ?
Cela va construire des boîtes qui contiendront 95% des pixels.
- Inscire un titre descriptif
- Nommer l'image de sortie => PIPEDZ
Valider avec Next =>
- Conserver tous les canaux d'enregistrement
Valider par OK
4) En quoi l'utilisation de la valeur de l'écart-type à la place du Min/Max modifie-t-elle le résultat de la classification par hypercube ?
Cette dernière méthode est basée sur l'analyse discriminante linéaire* :
q) Lancer FISHER
- Sélectionner l'insertion d'un Signature group file : TRSITES
- Nommer l'image de sortie => FISHER
- Inscire un titre descriptif
Valider par OK
r) Comparer chacune des classifications réalisées :
- MINDISTRAW
- MINDSISNORMAL
- MAXLIKE
- PIPEDMINMAX
- PIPEDZ
- FISHER
- Utiliser la palette Qualitative 256
- Afficher les toutes en même temps.
5) Quelle classisfication est la meilleure ? Pourquoi ?
- La comparaison est-elle facile ?
Il existe des indices facilitant l'analyse, qui comparent le résultat de la classification avec :
- une carte existante (couverture exhaustive) ;
ou
- une enquête de terrain (information fragmentaire).
- Afficher le fichier Introductory GIS\WORCWEST avec la palette WORCWEST
Avec la légende et le titre
- Sur quel secteur sommes-nous ?
Dans le NW de l'aéroport
- Avons-nous le même nombre de postes de légende ?
- Afficher les informations sur les fichiers WORCWEST et H87TM1 (par exemple)
Avec File/Metadata
- Quels sont les X et Y de l'un et de l'autre ?
- Qui est inclus dans qui ?
Puis :
- Laisser sélectionné par défaut Window only one image => seule WORCWEST sera redimensionnée
- Nommer l'image d'entrée => WORCWEST
- Nommer l'image de sortie => WORCWH87
- Recadrer sur une image déjà existante => H87TM1 (par exemple)
Constater que les X et Y de cette dernière s'affiche automatiquement
Min. X = 3 930
Max. X = 6 090
Min. Y = 1 020
Max. X = 3 600
Valider avec OK
- Prendre la meilleure classification
à défaut, on prendra MINDISTNORMAL
- Regrouper d'abord les deux classes d'eau qui ne sont pas séparées sur WORCWH87
Utiliser GIS Analysis/Database Query/RECLASS
- Laisser par défaut :
Image comme Type of file to reclass
User-defined reclass comme Classification type
- Nommer l'image d'entrée => MINDISTNORMAL
- Nommer l'image de sortie => CARTEODS
- Donner la valeur (Assigne a new value of) => 1
De la valeur (To all values from) => 2
Jusqu'à (To just less than) => 3
Cela revient à recoder l'ancienne classe 2 (Eau_prof) en 1 (E_peu_pr) qu'on appelera ensuite Eau.
- Puis incrémenter le curseur à l'aide des flèches de 1 à 2 pour modifier le reste des valeurs comme indiqué dans le tableau 1
tab. 1 - Modification de la légende de MINDISTNORMAL dans RECLASS
Nouvelle valeur De à Curseur Ancienne classe Nouvelle classe 1 2 3 1 E_peu_pr Eau 2 5 6 2 Eau_prof Feuillus 3 6 7 3 Culture Résineux 4 3 4 4 Zon_urba Cultures 5 4 5 5 Feuillus Sols artificialisés Valider avec OK
On va en profiter pour faire une palette cohérente avec la carte d'occupation des sols réalisée
- Lancer Display/Symbol Workshop
Puis
- File/New
- Symbol File Type => Palette
- Nommer le fichier palette => CARTE6CL
Valider par Ok
- Paramétrer les cellules comme suit :
tab. 2 - Nouvelles couleurs pour les classes d'occupation du sol
Classe d'Occupation du sol N° de classe Valeur du Rouge Valeur du Vert Valeur du Bleu Non classés 0 0 0 0 Eau 1 0 56 98 Feuillus 2 0 200 0 Résineux 3 0 150 0 Cultures 4 255 255 0 Sols artificialisés 5 255 0 0
Puis File/Save (CTRL + S)
- Quitter puis appliquer la palette à CARTEODS
Composer/Layer Properties
Palette file => CARTE6CL
- À quoi ressemble les postes de légende ?
Les renseigner dans Metadata/Legend
- Lancer File/Metadata
- Fichier à renseigner => CARTEODS
- Cliquer sur l'onglet Legend
- Remplir comme suit
tab. 3 - Modification de la légende de MINDISTNORMAL dans RECLASS
Legend categories Classe d'occupation du sol 0 Non classés 1 Eau 2 Feuillus 3 Résineux 4 Cultures 5 Sols artificialisés Valider avec OK
- Recharger la légende
- Qu'en pensez-vous ?
- L'image WORCWH87 contient également trop de postes d'occupation du sol pour être comparée à notre classification
- Faire les regroupements comme précédemment
Utiliser GIS Analysis/Database Query/RECLASS
- Laisser par défaut :
Image comme Type of file to reclass
User-defined reclass comme Classification type
- Nommer l'image d'entrée => WORCWH87
- Nommer l'image de sortie => WORCWREF
- Donner la valeur (Assigne a new value of) => 2
De la valeur (To all values from) => 3
Jusqu'à (To just less than) => 5
Cela revient à recoder les anciennes classes 2, 3 et 4 (Deciduous 1, 2 et 3) en 1 (Deciduous 1) qu'on appelera ensuite Feuillus.
- Puis incrémenter le curseur à l'aide des flèches de 1 à 2 pour modifier le reste des valeurs comme indiqué dans le tableau 4
tab. 4 - Modification de la légende de WORCWREF dans RECLASS
Comme vous pouvez le constater, on n'a pas touché aux classes 0 (Non classés) et 1 (Eau) qui sont déjà cohérentes avec notre classification reclassée CARTEODS.
Nouvelle valeur De à Curseur Ancienne classe Nouvelle classe 2 3 5 1 Deciduous 1, 2 et 3 Feuillus 3 5 7 2 Conifer 1 et 2 Résineux 4 8 9 3 Agriculture Cultures 5 7 8 4 Grass/Suburb Sols artificialisés 5 9 15 5 Urban à Baren Sols artificialisés Valider avec OK
- Modifier le .RDC de WORCWREF
Lancer File/Metadata
- Fichier à renseigner => WORCWREF
- Cliquer sur l'onglet Legend
- Remplir comme au tableau 3
- Afficher les fichiers images WORCWREF et CARTEODS côtes-à-côtes
- Lancer GIS Analysis/Decision Support/ERRMAT
- Nommer l'image de vérité terrain* (Ground truth image) => WORCWREF
- Nommer la carte issue de la classification* (Categorical map image) => CARTEODS
6) Quel est le thème qui a la plus forte erreur d'omission ?
- Quel est le thème qui a la plus forte erreur de commission ?
- La classification est-elle performante ?
La fiche mémo mem43tel.htm contient les informations nécessaires pour l'analyse des matrices d'erreur et des indices associés.
Conclusion :
- Quelle méthode de classification choisir ?
- Le minimum de distance :
- donne de bons résultats quand il est utilisé avec la distance standardisée ;
- est plus rapide que le maximum de vraisemblance ;
- est plus lent que la classification par hypercube ;
- supporte un faible nombre de pixels d'entraînement ;
- est assez tolérant vis-à-vis des problèmes de définition des parcelles d'entraînement.
- Le maximum de vraisemblance et l'analyse discriminante linéaire (FISHER) :
- produit des meilleurs résultats quand les sites d'entraînement sont très bons ;
- méthode la plus gourmande en temps de calcul.
- La méthode des hypercubes :
- peut donner de bons résultats avec l'option écart-type ;
- est la plus rapide.
Celle qui a la meilleure matrice de confusion globale ou pour le thème recherché !
Conserver les fichiers images MINDISTNORMAL et MAXLIKE pour les exercices de la fiche guide 4.4. Vous pouvez détruire les autres fichiers images
NB : les mots suivis de "*" font partie du vocabulaire géographique, donc leur définition doit être connue. Faites-vous un glossaire.